MongoDB, one of the leading NoSQL databases, is well known for its fast performance, flexible schema, scalability and great indexing capabilities. At the heart of this fast performance are MongoDB indexes, which support efficient query execution by avoiding full collection scans and thus limiting the number of documents that MongoDB searches.
Starting with version 2.4, MongoDB started with an experimental feature supporting full-text search using text indexes. This feature is now an integral part of the product (and no longer an experimental feature). Using MongoDB’s full-text search, you can define a text index on any field in the document whose value is a string or an array of strings. When we create a text index on a field, MongoDB tokenizes and slices the textual content of the indexed field, and sets up the indexes accordingly.
In this tutorial, we will explore the full-text search features of MongoDB.
CREATION OF A MONGODB SERVER ON HIDORA
First, we need to install MongoDB, so let’s see how quickly and easily MongoDB can be installed on the Hidora PaaS:
- Log in to the Hidora dashboard with your credentials.
- Click on Create environment in the upper left corner of the dashboard.
- In the Environment Topology dialog box, choose MongoDB as the database to use (it is in the NoSQL database drop-down list). Set the cloudlet boundaries for this node, type the name of your first environment and confirm the creation.

- Wait a minute until the process is complete.

CONNECTING TO THE MONGODB WITH SSH
Now let’s see how you can access your Hidora account with all its environments and containers.
Note. SSH access is provided to the whole account but not to a separate environment.
- Open the Hidora dashboard and go to the top toolbar.
- Click on the Settings button.
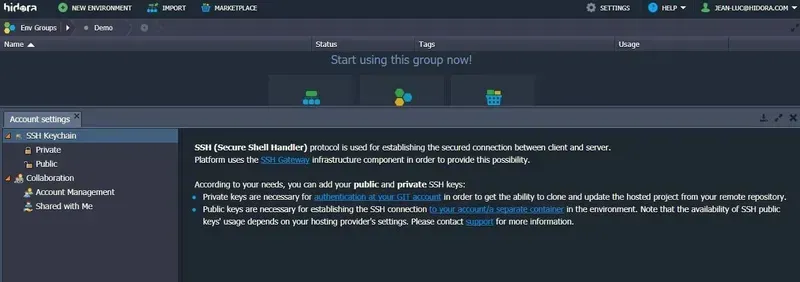
In the Settings tab of the open account, navigate to SSH Keychain > Public.
Note. The availability of this option is only activated for billing customers. If you need this access during the trial period, please let us know and we will grant you the necessary access.
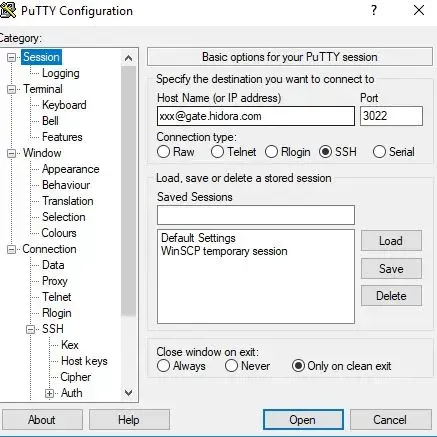
- Click on the link in the note to open your SSH door. This will automatically access the Shell Handler via the console. Or, simply copy the given command line and execute it via your console (SSH client).
CREATION OF A SAMPLE OF DATA
Data in MongoDB has a flexible schema. Unlike SQL databases, where you must determine and declare the schema of a table before inserting data, MongoDB collections do not impose the structure of documents. This flexibility makes it easy to map documents to an entity or object. Each document can match the data fields of the represented entity, even if the data has significant variations. In practice, however, documents in a collection share a similar structure.
The main challenge in data modelling is to balance the needs of the application, the performance characteristics of the database engine and the data recovery models. When designing data models, one must always consider the application’s use of the data (i.e. queries, updates and data processing) as well as the inherent structure of the data itself.
MongoDB stores data records as BSON documents. BSON is a binary representation of JSON documents, although it contains more data types than JSON. For the BSON specification, see bsonspec.org.
MongoDB stores BSON documents, i.e. data records, in collections; collections in databases. In MongoDB, databases contain collections of documents.
To select a database to use, in the mongo shell, issue the use use myDB If a database does not exist, MongoDB creates the database when you first store data for it. So you can switch to a non-existent database and perform the following operation in the mongo shell: use myNewDB The insertOne() operation creates both the myNewDB database and the myNewCollection1 collection if they do not already exist. MongoDB stores documents in collections. Collections are analogous to tables in relational databases. If a collection does not exist, MongoDB creates the collection when you first store data for it. db.myNewCollection2.insertOne( { x: 1 } ) The operations insertOne() and createIndex() create their respective collections if they do not already exist. MongoDB provides the db.createCollection() method to explicitly create a collection with various options, such as setting the maximum size or documentation validation rules. If you do not specify these options, you do not need to explicitly create the collection since MongoDB creates new collections when you first store data for collections. Starting with MongoDB 3.2, MongoDB introduces a version 3 of the text index MongoDB provides text indexes to support text search queries on the contents of strings. Text indexes can include any field whose value is a string or an array of string elements. IMPORTANT: A collection can have a maximum of one text index. To create a text index, use the db.collection.createIndex() method. To index a field that contains a string or array of string elements, include the field and specify the string literal “text” in the index document, as in the following example: db.reviews.createIndex( { comments: “text” } ) You can index multiple fields for the text index. The following example creates a text index on the subject and comments fields: db.reviews.createIndex( { subject: “text”, comments: “text” } ) A compound index can include text index keys in combination with ascending or descending index keys. To file a text index, use the index name. For a text index, the weight of an indexed field indicates the importance of that field relative to the other indexed fields in terms of the text search score. For each indexed field in the document, MongoDB multiplies the number of matches by the weight and sums the results. Using this sum, MongoDB then calculates the document score. The default weight is 1 for indexed fields. To adjust the weights of indexed fields, include the weights option in the db.collection.createIndex() method. When creating a text index across multiple fields, you can also use the wildcard specifier ($**). With a wildcard text index, MongoDB indexes each field containing string data for each document in the collection. The following example creates a text index using the wildcard specifier : db.collection.createIndex( { “$**”: “text” } ) This index allows textual searches to be performed on all fields containing strings. Such an index can be useful with very unstructured data if one does not know which fields to include in the textual index or for ad-hoc queries. Wildcard text indexes are text indexes over multiple fields. As such, you can assign weights to specific fields when creating the index to control the ranking of the results. Wildcard text indexes, like all text indexes, can be part of a compound index. For example, the following example creates a compound index on the field a and the wildcard specifier : db.collection.createIndex( { a: 1, “$**”: “text” } ) As with all compound text indexes, since the a precedes the text index key, to perform a $text search with this index, the query predicate must include an a equality condition. The version 3 text index supports common case folding C, simple case folding S and, for Turkish languages, special case folding T, as specified in the Unicode 8.0 Case Folding character database. Case folding extends the case insensitivity of the text index to include characters with diacritics, such as é and É, and characters from non-Latin alphabets, such as ‘И’ and ‘и’ in the Cyrillic alphabet. Version 3 of the textual index is also insensitive to diacritics. Thus, the index does not distinguish between é, É, e and E. Previous versions of the textual index are case insensitive for [A-z] only; that is, case insensitive for non-diacritical Latin characters only. For all other characters, previous versions of the textual index treat them as distinct. With version 3, the text index is insensitive to diacritical marks. In other words, the index does not distinguish between characters that contain diacritical marks and their unmarked counterparts, such as é, ê and e. Specifically, the text index eliminates characters of Unicode 8.. Version 3 of the text index is also case insensitive for characters with diacritics. For example, the index does not distinguish between é, É, e and E. Previous versions of the text index treat characters with diacritics as distinct. For tokenization, the version 3 text index uses delimiters categorized as Dash, Hyphen, Pattern_Syntax, Quotation_Mark, Terminal_Punctuation, and White_Space in the Prop list of the Unicode 8.0 character database. For example, given the string “He said he was the best player in the world”, the text index treats “,” and spaces as delimiters. Previous versions of the index treat “as part of the term ‘was’” and “as part of the term ‘world’”. The textual index tokenises and sorts the terms in the indexed fields for the index entries. The textual index stores an index entry for each unique term cleaned up in each indexed field for each document in the collection. The index uses simple stemming by language-specific suffix. MongoDB supports text searching in multiple languages. Text indexes ignore language-specific stop words (e.g., the, an, a, and, etc.) and use simple language-specific suffixes. For a list of supported languages, see Text search languages. If you specify the value “none” for the language, the text indexing uses simple tokenisation without stop word lists or derivations. Text indexes are sparse by default and ignore the sparse: true option. If a document has no text index field (or if the field is null or an empty array), MongoDB does not add an entry for the document to the text index. For inserts, MongoDB inserts the document but does not add anything to the text index. For a compound index that includes a text index key as well as keys of other types, only the text index field determines whether the index refers to a document. The other keys do not determine whether the index refers to documents or not. Only one text index per collection. A collection can have a maximum of one text index. Text search and advice You cannot use hint() if the query includes a $text query expression. Sort operations cannot obtain the sort order from a text index, even from a compound text index; that is, sort operations cannot use the order of the text index. A compound index can include a text index key in combination with ascending/descending index keys. However, these compound indexes have the following restrictions: To delete a text index, pass the index name to the db.collection.dropIndex() method. To get the index name, run the db.collection.getIndexes() method. Text indexes have the following storage requirements and performance costs: The text index supports $text search operations. For examples of text search, see the $text reference page. For examples of $text operations in the aggregation pipelines, see Searching for text in the aggregation pipeline. The full-text search does not work properly for very large datasets, as all matches are returned as a single document and the command does not support a “skip” parameter to retrieve results page by page. Although the search is only on the “_id” field, a huge result set will not be returned in its entirety if the result exceeds Mongo’s limit of 16 MB per document. A compound text index cannot include other types of indexes, such as multi-key or geo-spatial indexes. In addition, if your compound text index includes index keys before the text index key, all queries must specify equality operators for the preceding keys. Text indexes create an overhead when inserting new documents. This has the effect of reducing the insertion rate. Some queries, such as phrase searches, can be relatively slow. MongoDB’s full-text search is not offered as a complete replacement for search engine databases such as Elastic, SOLR, etc. However, it can be used effectively for most applications that are built with MongoDB today. However, it can be used effectively for the majority of applications that are built with MongoDB today.Creating a database
db.myNewCollection1.insertOne( { x: 1 } )Create a collection
db.myNewCollection3.createIndex( { y: 1 } )Explicit creation
DOCUMENT SEARCH
Create a text index
Specify weight
Index of greeting card texts
Case insensitivity
Insensitivity to diacritics
Tokenization delimiters
Index entries
Supported languages and stop words
Scattered ownership
Restrictions
Index and text sorting
Composite index
Submit a text index
Storage requirements and performance costs
Text search Support
IS THERE A WAY TO IMPROVE PERFORMANCE?
CONCLUSION