MongoDB, l’une des principales bases de données NoSQL, est bien connue pour ses performances rapides, son schéma flexible, son évolutivité et ses grandes capacités d’indexation. Au cœur de ces performances rapides se trouvent les index MongoDB, qui support exécution efficace des requêtes en évitant les balayages de collections complètes et en limitant ainsi le nombre de documents que MongoDB recherche.
À partir de la version 2.4, MongoDB a commencé avec une fonctionnalité expérimentale prenant en charge la recherche plein texte à l’aide d’index de texte. Cette fonctionnalité fait désormais partie intégrante du produit (et n’est plus une fonctionnalité expérimentale). En utilisant la recherche plein texte de MongoDB, vous pouvez définir un index de texte sur n’importe quel champ du document dont la valeur est une chaîne ou un tableau de chaînes. Lorsque nous créons un index de texte sur un champ, MongoDB tokenise et découpe le contenu textuel du champ indexé, et configure les index en conséquence.
Dans ce tutoriel, nous allons explorer les fonctionnalités de recherche en texte intégral de MongoDB.
CRÉATION D’UN SERVEUR MONGODB SUR HIDORA
Tout d’abord, nous devons installer MongoDB, alors voyons comment MongoDB peut être installé rapidement et facilement sur le PaaS Hidora :
- Connectez-vous au tableau de bord Hidora avec vos informations d’identification.
- Cliquez sur Créer un environnement dans le coin supérieur gauche du tableau de bord.
- Dans la boîte de dialogue Topologie de l’environnement, choisissez MongoDB comme base de données à utiliser (elle se trouve dans la liste déroulante des bases de données NoSQL). Définissez les limites de cloudlet pour ce nœud, tapez le nom de votre premier environnement et confirmez la création.

- Attendez une minute que le processus soit terminé.

CONNEXION À LA MONGODB AVEC SSH
Voyons maintenant comment vous pouvez accéder à votre compte Hidora avec tous ses environnements et conteneurs.
Note. L’accès SSH est fourni à l’ensemble du compte mais pas à un environnement séparé.
- Ouvrez le tableau de bord Hidora et accédez à la barre d’outils supérieure.
- Cliquez sur le bouton Paramètres.
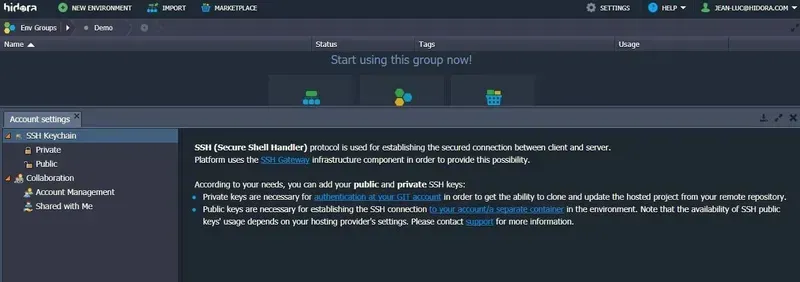
Dans l’onglet Paramètres du compte ouvert, accédez à l’option Trousseau de clés SSH > Public.
Note. La disponibilité de cette option n’est activée que pour les clients qui facturent. Si vous avez besoin de cet accès pendant la période d’essai, faites-le nous savoir et nous vous accorderons l’accès nécessaire.
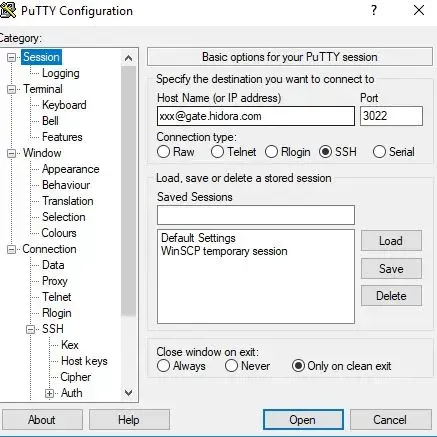
- Cliquez sur le lien dans la note pour ouvrir votre porte SSH. Ainsi, vous accéderez automatiquement au Shell Handler via la console. Ou bien, copiez simplement la ligne de commande donnée et exécutez-la via votre console (client SSH).
CRÉATION D’UN ÉCHANTILLON DE DONNÉES
Les données dans MongoDB ont un schéma flexible. Contrairement aux bases de données SQL, où vous devez déterminer et déclarer le schéma d’une table avant d’insérer des données, les collections de MongoDB n’imposent pas la structure des documents. Cette flexibilité facilite la mise en correspondance des documents avec une entité ou un objet. Chaque document peut correspondre aux champs de données de l’entité représentée, même si les données présentent des variations importantes. En pratique, cependant, les documents d’une collection partagent une structure similaire.
Le principal défi de la modélisation des données consiste à trouver un équilibre entre les besoins de l’application, les caractéristiques de performance du moteur de base de données et les modèles de récupération des données. Lors de la conception des modèles de données, il faut toujours prendre en compte l’utilisation des données par l’application (c’est-à-dire les requêtes, les mises à jour et le traitement des données) ainsi que la structure inhérente des données elles-mêmes.
MongoDB stocke les enregistrements de données sous forme de documents BSON. BSON est une représentation binaire des documents JSON, bien qu’il contienne plus de types de données que JSON. Pour la spécification BSON, voir bsonspec.org.
MongoDB stocke les documents BSON, c’est-à-dire les enregistrements de données, dans des collections ; les collections dans des bases de données. Dans MongoDB, les bases de données contiennent des collections de documents.
To select a database to use, in the mongo shell, issue the use utiliser myDB Si une base de données n’existe pas, MongoDB crée la base de données lorsque vous stockez pour la première fois des données pour cette base de données. Ainsi, vous pouvez passer à une base de données inexistante et effectuer l’opération suivante dans le shell mongo : use myNewDB L’opération insertOne() crée à la fois la base de données maNouvelleDB et la collection maNouvelleCollection1 si elles n’existent pas déjà. MongoDB stocke les documents dans des collections. Les collections sont analogues aux tables des bases de données relationnelles. Si une collection n’existe pas, MongoDB crée la collection lorsque vous stockez pour la première fois des données pour cette collection. db.myNewCollection2.insertOne( { x: 1 } ) Les opérations insertOne() et createIndex() créent leur collection respective si elle n’existe pas déjà. MongoDB fournit la méthode db.createCollection() pour créer explicitement une collection avec diverses options, comme la définition de la taille maximale ou les règles de validation de la documentation. Si vous ne spécifiez pas ces options, vous n’avez pas besoin de créer explicitement la collection puisque MongoDB crée de nouvelles collections lorsque vous stockez pour la première fois des données pour les collections. À partir de MongoDB 3.2, MongoDB introduit une version 3 de l’index texte MongoDB fournit des index de texte pour support des requêtes de recherche de texte sur le contenu des chaînes de caractères. Les index de texte peuvent inclure tout champ dont la valeur est une chaîne de caractères ou un tableau d’éléments de chaîne de caractères. IMPORTANT : Une collection peut avoir au maximum un index texte. Pour créer un index de texte, utilisez la méthode db.collection.createIndex(). Pour indexer un champ qui contient une chaîne de caractères ou un tableau d’éléments de chaîne de caractères, incluez le champ et spécifiez le littéral de chaîne de caractères « text » dans le document d’index, comme dans l’exemple suivant : db.reviews.createIndex( { comments: “text” } ) Vous pouvez indexer plusieurs champs pour l’index texte. L’exemple suivant crée un index texte sur les champs sujet et commentaires : db.reviews.createIndex( { subject: “text”, comments: “text” } ) Un index composé peut inclure des clés d’index texte en combinaison avec des clés d’index ascendantes ou descendantes. Pour déposer un index texte, il faut utiliser le nom de l’index. Pour un index de texte, le poids d’un champ indexé indique l’importance de ce champ par rapport aux autres champs indexés en termes de score de recherche de texte. Pour chaque champ indexé du document, MongoDB multiplie le nombre de correspondances par le poids et additionne les résultats. En utilisant cette somme, MongoDB calcule ensuite le score du document. Le poids par défaut est de 1 pour les champs indexés. Pour ajuster les pondérations des champs indexés, incluez l’option weights dans la méthode db.collection.createIndex(). Lorsque vous créez un index texte sur plusieurs champs, vous pouvez également utiliser le spécificateur de caractère générique ($**). Avec un index de texte avec caractère de remplacement, MongoDB indexe chaque champ contenant des données de type chaîne pour chaque document de la collection. L’exemple suivant crée un index texte en utilisant le spécificateur de caractère générique : db.collection.createIndex( { “$**”: “text” } ) Cet index permet d’effectuer des recherches textuelles sur tous les champs contenant des chaînes de caractères. Un tel index peut être utile avec des données très peu structurées si l’on ne sait pas quels champs inclure dans l’index textuel ou pour des requêtes ad-hoc. Les index de texte avec caractères génériques sont des index de texte sur plusieurs champs. En tant que tels, vous pouvez attribuer des pondérations à des champs spécifiques lors de la création de l’index afin de contrôler le texte avec caractères génériques, comme tous les index de texte, peuvent faire partie d’un index composé. Par exemple, l’exemple suivant crée un index composé sur le champ a ainsi que sur le spécificateur de caractère générique : db.collection.createIndex( { a: 1, “$**”: “text” } ) Comme pour tous les index textuels composés, puisque le a précède la clé de l’index textuel, pour effectuer une recherche $text avec cet index, le prédicat de la requête doit inclure une condition d’égalité a. L’index de texte de la version 3 prend en charge les pliages de casse communs C, simples S et, pour les langues turques, les pliages de casse spéciaux T, comme spécifié dans la base de données de caractères Unicode 8.0 Case Folding. Le pliage en casse étend l’insensibilité à la casse de l’index du texte pour inclure les caractères avec diacritiques, comme é et É, et les caractères des alphabets non latins, comme « И » et « и » dans l’alphabet cyrillique. La version 3 de l’index textuel est également insensible aux diacritiques . Ainsi, l’index ne fait pas non plus la distinction entre é, É, e et E. Les versions précédentes de l’index textuel sont insensibles à la casse pour [A-z] seulement ; c’est-à-dire insensibles à la casse pour les caractères latins non diacritiques seulement. Pour tous les autres caractères, les versions précédentes de l’index textuel les traitent comme distincts. Avec la version 3, l’index textuel est insensible aux signes diacritiques. En d’autres termes, l’index ne fait pas de distinction entre les caractères qui contiennent des signes diacritiques et leurs homologues non marqués, tels que é, ê et e. Plus précisément, l’index textuel élimine les caractères Prop List de Unicode 8.0. La version 3 de l’index textuel est également insensible à la casse des caractères avec diacritiques. Ainsi, l’index ne fait pas non plus la distinction entre é, É, e et E. Les versions précédentes de l’index textuel traitent les caractères avec diacritiques comme distincts. Pour la tokenisation, l’index de texte de la version 3 utilise les délimiteurs catégorisés sous Dash, Hyphen, Pattern_Syntax, Quotation_Mark, Terminal_Punctuation, et White_Space dans la liste Prop de la base de données de caractères Unicode 8.0. Par exemple, si on lui donne la chaîne « Il a dit qu’il « était le meilleur joueur du monde » », l’index textuel traite les « , » et les espaces comme des délimiteurs. Les versions précédentes de l’index traitent » comme une partie du terme « »était » » et » comme une partie du terme « monde » ». L’index textuel tokenise et strie les termes dans les champs indexés pour les entrées d’index. L’index textuel stocke une entrée d’index pour chaque terme unique épuré dans chaque champ indexé pour chaque document de la collection. L’index utilise un stemmage simple par suffixe spécifique à la langue. MongoDB prend en charge la recherche de texte dans plusieurs langues. Les index de texte ne tiennent pas compte des mots d’arrêt spécifiques à la langue (par exemple, en anglais, the, an, a, and, etc.) et utilisent des suffixes simples spécifiques à la langue. Pour obtenir une liste des langues prises en charge, consultez la rubrique Langues de recherche de texte. Si vous spécifiez la valeur « none » pour la langue, l’indexation du texte utilise une simple tokénisation sans liste de mots d’arrêt ni dérivation. Les index de texte sont épars par défaut et ignorent l’option sparse : true. Si un document n’a pas de champ d’index texte (ou si le champ est nul ou un tableau vide), MongoDB n’ajoute pas d’entrée pour le document à l’index texte. Pour les insertions, MongoDB insère le document mais n’ajoute rien à l’index de texte. Pour un index composé qui comprend une clé d’indexation de texte ainsi que des clés d’autres types, seul le champ d’indexation de texte détermine si l’index fait référence à un document. Les autres clés ne déterminent pas si l’index fait référence aux documents ou non. Un seul index de texte par collection. Une collection peut avoir au maximum un index texte. Recherche de texte et conseils Vous ne pouvez pas utiliser hint() si la requête comprend une expression de requête $text. Les opérations de tri ne peuvent pas obtenir l’ordre de tri à partir d’un index de texte, même d’un index de texte composé ; c’est-à-dire que les opérations de tri ne peuvent pas utiliser l’ordre de l’index de texte. Un index composé peut inclure une clé d’indexation de texte en combinaison avec des clés d’indexation ascendantes/descendantes. Toutefois, ces index composés présentent les restrictions suivantes : Pour supprimer un index de texte, passez le nom de l’index à la méthode db.collection.dropIndex(). Pour obtenir le nom de l’index, exécutez la méthode db.collection.getIndexes(). Les index de texte ont les exigences de stockage et les coûts de performance suivants : L’index texte supporte les opérations de recherche $text. Pour des exemples de recherche de texte, voir la page de référence $text. Pour des exemples d’opérations $text dans les pipelines d’agrégation, voir Recherche de texte dans le pipeline d’agrégation. La recherche en texte intégral ne fonctionne pas correctement pour les ensembles de données très volumineux, car toutes les correspondances sont renvoyées sous la forme d’un document unique et la commande n’est pas support un paramètre « skip » pour récupérer les résultats page par page. Bien que la recherche ne porte que sur le champ « _id », un énorme ensemble de résultats ne sera pas renvoyé dans son intégralité si le résultat dépasse la limite de 16 Mo par document fixée par Mongo. Un index textuel composé ne peut pas inclure d’autres types d’index, comme les index multi-clé ou les index géo-spatiaux. De plus, si votre index textuel composé comprend des clés d’indexation avant la clé d’indexation textuelle, toutes les requêtes doivent spécifier les opérateurs d’égalité pour les clés précédentes. Les index de texte créent une surcharge lors de l’insertion de nouveaux documents. Cela a pour effet de réduire le débit d’insertion. Certaines requêtes, comme les recherches de phrases, peuvent être relativement lentes. La recherche en texte intégral de MongoDB n’est pas proposée comme un remplacement complet des bases de données à moteur de recherche comme Elastic, SOLR, etc. Cependant, elle peut être utilisée efficacement pour la majorité des applications qui sont construites avec MongoDB aujourd’hui. Matthieu Robin est le CEO de Hidora, un leader stratégique expérimenté, un ancien administrateur système qui a géré et configuré plus d’environnements manuellement que quiconque sur la planète et après avoir compris que cela pouvait être fait en quelques clics a créé Hidora SA. Il intervient régulièrement lors de conférences et aide les entreprises à optimiser leurs processus métier grâce à DevOps. Suivez-le sur Twitter @matthieurobin.Créer une base de données
db.myNewCollection1.insertOne( { x: 1 } )Créer une collection
db.myNewCollection3.createIndex( { y: 1 } )Création explicite
RECHERCHE DE DOCUMENTS
Créer un index de texte
Précisez le poids
Index des textes des cartes de vœux
Insensibilité aux cas
Insensibilité aux diacritiques
Délimiteurs de tokenisation
Entrées d’index
Langues prises en charge et mots d’arrêt
Propriété éparse
Restrictions
Index et tri de texte
Indice composé
Déposer un index de texte
Exigences de stockage et coûts de performance
Recherche de texte Support
EXISTE-T-IL UN MOYEN D’AMÉLIORER LES PERFORMANCES ?
CONCLUSION
Écrit par