Une application micro-services
Supposons que nous développions une application de micro-services, par exemple une boutique en ligne. En substance, notre boutique en ligne consiste en une application frontale qui communique avec un backend par le biais d’une API. Par souci de simplicité, disons que notre backend ressemble à ceci :
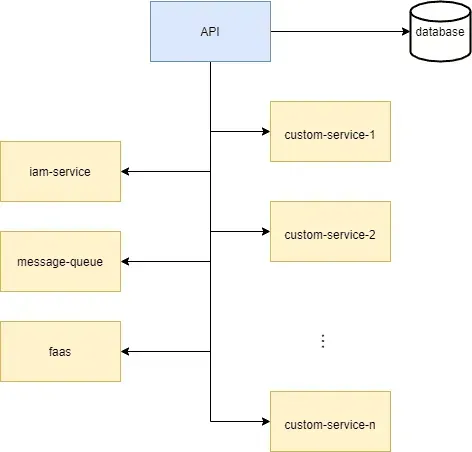
La gestion des utilisateurs est assurée par le service iam. Les commandes sont traitées via la file d’attente de messages. La plupart de la logique métier de notre backend est emballée dans des fonctions serverless servies par le faas. L’état de notre application est conservé dans notre base de données. Enfin, pour quelques bonnes raisons (par exemple, la facilité de configuration des tests), nous développons notre logiciel dans un monorepo.
Avec le temps, notre application micro-services contiendra nécessairement beaucoup de logique métier qui sera emballée dans encore plus de code micro-service ou de fonctions serverless. Par exemple, nous pourrions avoir besoin d’un service connecteur entre notre file d’attente de messages et notre faas, ou d’un service d’actifs avec une certaine logique pour ajouter de nouveaux actifs de manière contrôlée. Une façon très pratique d’héberger nos microservices est de les dockeriser et de laisser Kubernetes les orchestrer.
Généralement, notre service IAM est un tiers comme keycloak ou fusionauth que nous pouvons facilement déployer sur Kubernetes au moyen d’un diagramme helm. Helm est un gestionnaire de paquets très pratique pour Kubernetes. Par exemple, un déploiement typique de fusionauth ressemblerait à quelque chose de ce genre :
Notre file d’attente de messages est probablement redismq, rabbitmq ou kubemq, pour lesquels nous trouvons aussi facilement des diagrammes de barre.
Viennent ensuite nos propres services personnalisés pour lesquels nous devons écrire nos propres ressources Kubernetes (déploiements, services, ingresses, etc.). Enfin, nous pouvons écrire une sorte de script pour installer tous les diagrammes de barre nécessaires et appliquer nos ressources Kubernetes.
Parce que notre logiciel traite des données sensibles et fait notre métier, nous devons être prudents lorsque nous déployons une nouvelle version. Par conséquent, nous voulons d’une certaine manière la tester avant de la diffuser, ce qui est très facile à faire sur les clusters Kubernetes. En effet, nous pouvons imaginer que nous avons deux environnements, un pour les tests et un pour la production. L’environnement de test (ou staging) serait synchronisé avec la branche principale de notre dépôt de logiciels tandis que l’environnement de production serait le pendant de la branche de production de notre dépôt. Nous développons sur la branche principale et, dès que le Q&A est satisfait du logiciel qui y est poussé, nous le poussons vers la production.
Nous sommes maintenant dans une situation compliquée où nous voulons développer notre logiciel sur une machine de développement, le tester d’une manière ou d’une autre sur un environnement presque productif, et le diffuser dans un environnement de production. Cela nous conduit à trois procédures de construction et de déploiement différentes. Sur une machine de développement, nous voulons sûrement interagir avec une base de données éphémère. De plus, les identifiants de connexion à nos microservices (comme le service de gestion des actifs) doivent être triviaux. Sur une machine de développement, nous pouvons souhaiter accorder un accès non protégé à certains de nos services, à des fins de débogage. En production, nous voulons sécuriser et cacher autant que possible.
Enfin, si notre environnement de développement était proche de l’environnement de production, nous réduirions au minimum les surprises qui suivent un déploiement vers le staging ou la production, ce qui augmenterait notre productivité.
Entrer dans le devspace
Devspace est un outil de clique qui permet d’automatiser à la fois la construction et le déploiement d’images de conteneurs. En outre, cet outil pourrait aussi bien remplacer nos configurations makefile ou docker-compose et nous offre la possibilité de faire du développement basé sur Kubernetes. Grâce à cette dernière possibilité, supposons que nous ayons mis en place un petit cluster sur notre machine de développement. En un clic, vous pouvez demander à Jelastic de configurer ce cluster de développement pour vous via une interface très simple.
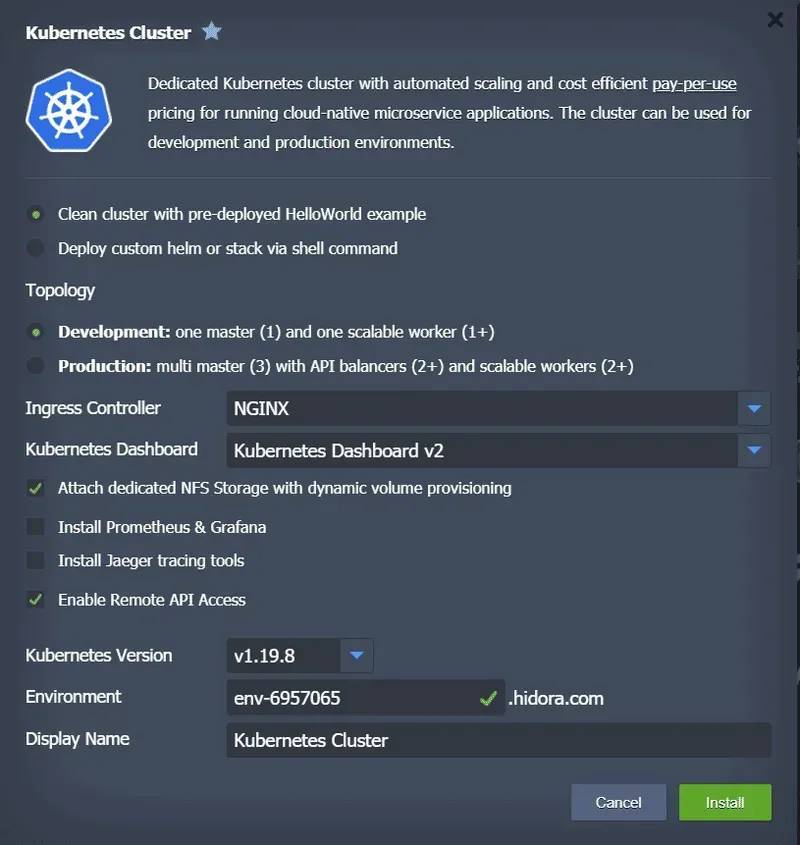
Vous pouvez également configurer manuellement votre propre cluster de bureau de type, minikube ou docker.
La façon la plus simple d’installer devspace (non pas sur votre cluster Kubernetes, mais sur une machine distante à partir de laquelle vous développez votre code !
Ensuite, en fonction de notre cas d’utilisation, nous pourrions exécuter
et suivez les instructions. Dans notre cas particulier, nous voulons construire
- notre API
- un ensemble de micro-services personnalisés
C’est ce que nous faisons avec la configuration suivante :
La configuration ci-dessus définit la manière de construire notre API et nos micro-services. Lorsqu’elles sont poussées vers leur registre docker, les deux images docker auront la même étiquette aléatoire (définie par la variable intégrée DEVSPACE_RANDOM). Au lieu d’utiliser un démon docker, nous pouvons également choisir d’utiliser des commandes de construction personnalisées ou kaniko. Nous pouvons utiliser des variables d’environnement, comme SOME_IMPORTANT_VARIABLE et fournir les options habituelles pour construire des images docker.
Ensuite, nous voulons déployer
- notre API
- nos micro-services personnalisés
- divers services tiers (iam, message queue, faas, assets)
Pour s’en occuper, nous complétons la configuration précédente avec le snippet suivant :
Le premier déploiement, my-custom-service, se résume à
Le deuxième déploiement, api, est une installation helm ordinaire. Au lieu d’écrire notre propre diagramme helm, nous aurions pu utiliser les diagrammes de composants intégrés qui offrent un compromis entre la définition de nos propres diagrammes helm et la simplicité de la configuration de nos ressources Kubernetes. Avec la configuration actuelle de notre devspace en place, nous pouvons démarrer notre environnement de développement :
Cette commande construit nos images docker et déploie notre logiciel dans l’espace de noms par défaut de notre cluster Kubernetes de développement. Nous sommes maintenant dans une situation où nous pouvons développer notre code sur notre machine de développement et le pousser vers notre cluster Kubernetes de développement. Avec le rechargement à chaud ou le rechargement automatique, nous pouvons même corriger notre code et le résultat est automatiquement propagé à notre cluster.
Déployer dans plusieurs environnements
Nous avons maintenant une configuration qui fonctionne pour le développement. Nous ne sommes pas très loin de la configuration de notre environnement de mise en scène. Premièrement, nos images docker doivent être marquées en suivant le modèle /:staging-. Deuxièmement, notre environnement de staging repose sur une base de données externe et des services IAM. Par conséquent, nous ne voulons pas les déployer sur staging et nous devons adapter les services qui en dépendent. Dans devspace, nous pouvons définir des profils. Jusqu’à présent, notre configuration ne fait référence à aucun profil, il s’agit donc du profil de développement. Nous pouvons définir le profil de staging, le laisser se baser sur le profil de développement et l’adapter comme nous venons de le décrire. Pour ce faire, ajoutons la configuration suivante à notre devspace.yaml :
Nous pouvons bien sûr suivre la même philosophie couplée au concept de profils parents pour définir notre profil de production. Ensuite, la construction et le déploiement vers la phase de test ou la production sont aussi simples que
Évidemment, le débogage à distance de ces profils est également possible.
Nous n’avons fait qu’effleurer la surface…
De nombreuses autres fonctionnalités sont disponibles, comme la définition de commandes personnalisées, la redirection (inverse) de ports, la synchronisation de fichiers, le streaming des journaux de conteneurs, etc . Utilisé judicieusement dans les pipelines CI / CD, devspace peut simplifier considérablement la façon dont vous publiez vos logiciels.