En tant que Product Owner (PO), je ne supporte pas que mon équipe ne livre pas l’incrément (dans son intégralité !) qu’elle avait promis à la fin du sprint. En effet, je passe du temps avec mes clients pour découvrir ce qu’ils veulent. Ensuite, je conçois des fonctionnalités utilisateur que je transforme en work packages. J’établis ensuite les priorités, je les affine et je les planifie avec l’équipe. Nous concluons même un accord ensemble avant de commencer un nouveau sprint. Après tout cela, lorsque mon équipe ne fournit pas tout ce à quoi elle s’était engagée, j’ai la désagréable impression que tout ce travail de préparation n’a été qu’un effort inutile. Tous ces frais généraux SCRUM pour rien ! Je me sens comme Rigor Mortis dans Oui, Seigneur des Ténèbres:

« – Nous n’avons pas vu venir ce problème »
« – Cela a pris plus de temps que prévu »
« – La bibliothèque est mal documentée »
« – Notre système de référence était en panne »
« – Nous ne l’avons pas compris de cette façon »
« – Quelqu’un de l’équipe a été malade pendant trois jours »,
would say, for example, my teams of goblins to creatively justify why they don’t deliver on specification at the end of the sprint. Because they failed, some features have to be postponed to a later sprint, therefore they are not delivered on time. Sometimes, bugs would be discovered during software demonstrations to our customers. Suddenly, the software just doesn’t work, « for no reason », and the goblins invoke the « demo effect ». In the end, Rigor Mortis has no other choice than doling out the withering look.

Bien sûr, je peux aussi, en tant que PO, être responsable de l’échec. Parfois, je guidais mes équipes de lutins vers les mauvaises fonctionnalités. Nous connaissons tous, en effet, la caricature de la gestion de projet en forme de balancier:

Il est assez facile pour un PO de mal comprendre les besoins des clients et même lorsqu’il les comprend correctement, le PO peut échouer dans sa mission de communiquer ce qu’il veut à l’équipe. De même, lorsque le PO utilise des moyens inappropriés pour suivre les progrès de l’équipe, il est entièrement responsable de l’échec. Discuter avec les membres de l’équipe (par exemple, lors des réunions quotidiennes) ne suffit pas pour avoir un aperçu de ce qui se passe. Au contraire, ce dont le PO a besoin, ce sont des chiffres pour évaluer les progrès. Comme l’a dit Lord Kelvin, « lorsque vous pouvez mesurer ce dont vous parlez et l’exprimer en chiffres, vous en savez quelque chose ; mais lorsque vous ne pouvez pas le mesurer, lorsque vous ne pouvez pas l’exprimer en chiffres, votre connaissance est maigre et insatisfaisante ». Dans le développement de logiciels, « le logiciel fonctionnel est la principale mesure du progrès », comme l’indique le 7e principe agile. Par conséquent, nous devons trouver un moyen de relier ce que notre client veut avec ce que notre équipe développe d’une manière mesurable, et c’est précisément ce que je voudrais aborder maintenant en présentant … un outil de communication gratuit.
Il est temps d’échapper à l’enfer de la rigidité cadavérique.
Fermons la parenthèse agile pour l’instant et concentrons-nous sur les problèmes réels. Supposons qu’un client vienne et demande :
« – hé, je voudrais que vous ajoutiez une fonctionnalité de connexion à ma plateforme »
Nous avons deux problèmes. D’une part, nous devons déterminer exactement ce qu’ils veulent. D’autre part, nous devons nous assurer que notre équipe logicielle comprend précisément ce que nous voulons et qu’elle trouve elle-même comment y parvenir de manière efficace et fiable.
Du client aux « trois amigos ».
Selon le client, la fonctionnalité peut être résumée par l’histoire d’utilisateur suivante :
> **En tant que directeur de magasin, > > je veux me connecter au tableau de bord de gestion, > > afin de pouvoir accéder aux données sensibles de mon magasin.**
Mais, bon, cette histoire d’utilisateur comporte de nombreux aspects. Pour commencer, le client doit décider du type d’informations d’identification qu’il souhaite utiliser. Un ensemble nom d’utilisateur / mot de passe ? Le nom d’utilisateur peut-il être un courriel ? Veut-il activer l’authentification multifactorielle (AMF)? Par ailleurs, accepte-t-on n’importe quel mot de passe ou applique-t-on une politique de mot de passe? En outre, combien de temps une connexion doit-elle rester valide ? Faut-il une fonction « se souvenir de moi » ? Enfin, à quoi doit ressembler visuellement cette fonction ?
Une discussion avec le client pourrait aboutir à la spécification suivante du Gherkin:
Feature: Manager can log on the management dashboard
As a shop manager,
I want to log on the management dashboard,
so that I can access my shop's sensitive data.
Scenario: The manager provides valid credentials on the admin application
Given a registered manager
When she logs on the admin application with valid email and password
Then she is granted access to her dashboard
Scenario: The manager provides wrong credentials
Given a registered manager
When she logs on the admin application with invalid credentials
Then she gets unauthorized access
--
Feature: Password policy
As a user,
I need to be encouraged to employ strong passwords,
for the sake of security.
Scenario Outline: The password is invalid
A password complies to the password policy if, and only if,
it satisfies the following criteria:
- contains at least 8 characters
- mixes alpha-numerical characters
- contains at least one special character
Given the password <non-compliant password=""/>
Then it is not compliant
Examples:
| non-compliant password |
| 1234 |
| 1l0v3y0u |
| ufiDo_anCyx |
| blabli 89qw lala hI |
C’est un résumé de notre discussion avec le client. Nous nous sommes mis dans la situation d’un manager utilisant le système et nous avons proposé des cas d’utilisation ou des scénarios. Notez que la spécification ci-dessus est écrite avec la syntaxe Gherkin mais vous pouvez choisir la syntaxe de votre choix. En ce qui me concerne, j’aime utiliser la syntaxe Gherkin, qui est prise en charge par de nombreux langages de programmation, ou la syntaxe gauge markdown, qui est prise en charge par moins de langages de programmation (C#, Java, Javascript, Python et Ruby, au moment de la rédaction de cet article). Vous pouvez trouver plus d’informations sur ces deux possibilités ici, ainsi que sur d’autres choix.
En plus de la spécification ci-dessus, le client nous donne carte blanche pour les aspects visuels. C’est tout pour les cas d’utilisation de haut niveau. En substance, ils ne veulent pas de MFA ni de fonction « se souvenir de moi ». Au lieu de cela, ils veulent rester simples et stupides, avec une authentification de base par email / mot de passe et une politique de mot de passe simple.
Cependant, l’histoire ne s’arrête pas là. La fonctionnalité doit être mise en œuvre et c’est là que nous impliquons les « trois amigos ». Bien qu’il soit agréable d’avoir défini clairement ce que le client souhaite, il peut manquer des scénarios permettant de vérifier « ce qui se passerait si… ». Par exemple, nos développeurs et testeurs pourraient trouver d’autres mots de passe non conformes. En outre, les caractéristiques de haut niveau ci-dessus ne couvrent certainement pas l’ensemble de la fonction de connexion. Par exemple, qu’est-ce que cela signifie d’être connecté ? Comment pouvons-nous valider la connexion ? L’équipe peut choisir (mais ce n’est pas une obligation) d’opter pour une authentification paseto ou JWT, pour laquelle la fonctionnalité suivante, plus technique, pourrait être conçue :
Feature: Authenticated users validate their JWTs
As a user,
I want to validate my JWT,
so that I can infer if my session is still valid.
Scenario: A valid JWT validates
Given a registered user
And the user has logged in with valid credentials
When she validates her JWT
Then she gets her user id
Scenario: An expired JWT does not validate
Given a registered user
When she validates an expired JWT
Then she gets error message
"""
Could not verify JWT: JWT expired
"""
Scenario: A JWT with inconsistent payload does not validate
Given a registered user
And the user has logged in with valid credentials
When she modifies the JWT payload
And validates the JWT
Then she gets error message
"""
Could not verify JWT: JWT error
"""
Scenario Outline: A non-JWT does not validate
Given the non-JWT "<non-jwt>"
When the user validates the JWT
Then she gets error message
"""
<error message=""/>
"""
Examples:
| description | non-jwt | error message |
| random string | my-invalid-jwt | Could not verify JWT: not a jwt |
| empty string | | Could not verify JWT: empty token |
Notez au passage comment notre user story initiale correspond à trois fonctionnalités Gherkin différentes. Il n’y a pas de correspondance entre les user stories et les fonctionnalités Gherkin, sauf, peut-être, dans la phase initiale d’un projet. Les user stories sont un outil de planification alors que les fonctionnalités Gherkin sont un outil de communication. Ils ne vivent pas sur la même couche.
Nous pouvons imaginer toutes sortes de processus agiles / v-model / autres pour discuter de la spécification mise à jour avec le client ou les parties prenantes et accroître la clarté de la fonctionnalité. Il s’agit d’une communication commerciale de haut niveau sur ce à quoi la fonctionnalité doit ressembler.
Néanmoins, bien que nous puissions dire que nous avons clarifié ce qu’il y a à faire, il est encore difficile d’estimer quand la fonction de connexion sera livrée, car nous n’avons pas encore réfléchi à la manière de la réaliser. Afin d’établir cette estimation, mettons en œuvre les tests ci-dessus. En effet, nous disposons maintenant de fichiers texte contenant la façon dont la fonctionnalité est censée se comporter. Pourquoi ne pas écrire un code qui émulerait un manager essayant de se connecter à son tableau de bord ? Lorsque l’équipe de développement le fera, elle découvrira les interfaces, les objets et les API de haut niveau avec lesquels elle doit interagir, ce qui permettra de définir l’architecture globale de notre fonctionnalité de connexion. Comme l’écrit Oncle Bob dans son livre Agile Software Development, Principles, Patterns, and Practices, « le fait de commencer par écrire des tests d’acceptation a un effet profond sur l’architecture du système » (chapitre 4, « Testing »). C’est en quelque sorte le même genre d’expérience que celle de l’oncle Bob et de Robert S. Koss dans The Bowling Game : An example of test-first pair programming, sauf que cette expérience se concentre sur les tests unitaires, donc sur les détails d’implémentation, plutôt que sur l’architecture globale du système. Selon la structure de votre organisation, l’ensemble de l’équipe, les architectes ou les chefs d’équipe écriront ces tests pour préparer la planification. Ce faisant, ils tomberont sûrement sur des surprises et pourraient même mettre à mal la fonctionnalité, afin d’acquérir les meilleures connaissances sur le sujet. Si nous pouvons éviter un « poker » de planification (ou équivalent), nous réduisons considérablement le risque de tromper nos parties prenantes. Plus l’équipe obtient d’informations sur la mise en œuvre, moins le poker sera risqué.
Prenons un scénario simple comme exemple pour illustrer comment la spécification pourrait être liée au code de test. Supposons que nous voulions implémenter
> Scénario : Un JWT valide
>
> Étant donné un utilisateur enregistré
> Et l’utilisateur s’est connecté avec des informations d’identification valides
> Lorsqu’il valide son JWT
> il obtient son identifiant d’utilisateur
Une implémentation possible en python pourrait ressembler à ceci (par exemple, avec la bibliothèque behave) :
@given(u'a registered user')
def step_impl(context):
# the auth_fixtures contain registered user data
context.current_user = context.auth_fixtures[0]
@given(u'the user has logged in with valid credentials')
def step_impl(context):
user = User(context)
# the Use client
context.current_jwt, _ = user.login(
context.current_user['email'], context.current_user['password'])
@when(u'she validates her JWT')
def step_impl(context):
token = context.current_jwt
# this method abstracts out communication with the api through a client
# it makes a context.response_payload available, which will be used in the "then" step
validate_token(context, token)
@then(u'she gets her user id')
def step_impl(context):
assert context.response_payload['userId'] == context.current_user['id']
Ce code est le résultat des débats architecturaux de l’équipe. Les membres de l’équipe trouvent des compromis, recherchent des technologies et font des pointes, jusqu’à ce qu’ils arrivent à un ensemble complet d’étapes Gherkin implémentées déclenchant la mise en œuvre la plus pragmatique, la plus minimaliste et la plus rentable des fonctionnalités souhaitées.
L’extrait de code python ci-dessus utilise le logiciel que votre équipe va développer. Avant le début d’une itération de développement, les scénarios ne s’exécutent pas, en raison de l’absence d’implémentation. Au fur et à mesure que le temps passe, de plus en plus de ces scénarios Gherkin fournissent un feedback de réussite. Lorsque l’équipe en a terminé avec la mise en œuvre, ce code fonctionne parfaitement et fournit une documentation vivante sur ce qui se passe dans le logiciel. Cette documentation est très puissante. Chaque fonctionnalité peut être fournie avec des décisions architecturales, des croquis et un lien direct avec l’exécution d’un code productif.
Nous disposons désormais d’une spécification et de ses tests sous-jacents. Notre équipe sait ce qu’ il faut faire et comment le faire. Lorsqu’elle exécute ces tests, elle sait à quel point elle a progressé vers son objectif. La planification / l’attribution des tâches est facile car les fonctionnalités ont été affinées et mises en évidence. Si l’équipe de développement met en œuvre l’intégration continue, Rigor Mortis peut même obtenir un retour d’information en direct sur la progression du développement. Lorsque ses lutins sont en mission, il peut surveiller leurs activités et avoir une meilleure idée de ce qu’ils font et de la façon dont ils le font, par exemple au moyen d’un tableau de bord du type suivant, qui serait mis à jour à chaque poussée de lutin vers la branche principale du référentiel :
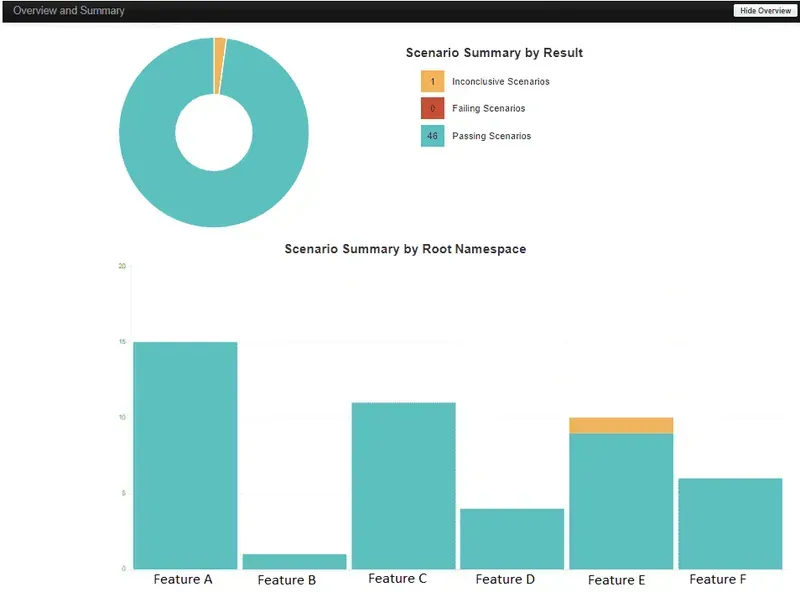
Ce sont précisément les chiffres dont nous avons parlé plus tôt dans ce post. Le tableau de bord montre clairement combien de scénarios sont réussis, échoués ou non concluants. Nous pouvons mettre des chiffres sur la progression du développement. Nous pouvons mesurer la quantité de logiciel fonctionnel que l’équipe a produit jusqu’à présent. D’après les résultats décrits par ce tableau de bord particulier, nous pouvons en déduire que l’équipe est bientôt prête à livrer les histoires d’utilisateur qu’elle s’est engagée à livrer.
Il est assez facile de mettre en place ce reporting et cette documentation en direct. Par exemple, avec le serveur Gitlab de la place de marché Jelastic sur Hidora,
ou avec le remarquable Gitlab as a Service de Hidora, vous pouvez définir des tâches de pipeline sur votre dépôt qui effectuent les tests Gherkin, emballent leurs résultats dans un fichier xml, génèrent le rapport pickles et le publient d’une manière ou d’une autre. En supposant que vous disposez d’une image docker pouvant être extraite d’un registre docker, par exemple
FROM mono:latest AS unpacker
ARG RELEASE_VERSION=2.20.1
ADD https://github.com/picklesdoc/pickles/releases/download/v${RELEASE_VERSION}/Pickles-exe-${RELEASE_VERSION}.zip /pickles.zip
RUN apt-get update \
&& apt-get install unzip \
&& mkdir /pickles \
&& unzip /pickles.zip -d /pickles
FROM mono:latest
COPY --from=unpacker /pickles /pickles
vous pouvez par exemple compléter vos pipelines gitlab comme ceci dans .gitlab-ci.yaml pour un projet de test d’acceptation SpecFlow:
stages:
- build
- test
- deploy
- review
- publish-pickles-reports
[...]
# here you deploy e.g. your staging environment
# the scripts are kept to their minimum for the sake of readability
# usually, you would want to ensure that your environment is in stopped state
# and you would also want to wait until all k8s deployments / jobs have been deployed
deploy:
stage: deploy
image: my-docker-registry/devspace:latest
variables:
<your deployment="" variables=""/>
environment:
name: $YOUR_STAGING_ENV_NAME
# we deploy to our staging domain
url: $URL_TO_YOUR_STAGING_ENVIRONMENT
before_script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
script:
- devspace deploy --build-sequential -n $KUBE_NAMESPACE -p staging
only:
- master
# here you perform your acceptance tests on the deployed system
acceptance-test:
stage: review
image: mcr.microsoft.com/dotnet/sdk:5.0-alpine-amd64
variables:
<your acceptance="" test="" variables=""/>
script:
# this command assumes you have JunitXml.TestLogger and NunitXml.TestLogger installed in your .net core / .net 5 project
- |
dotnet test ./features/Features.csproj --logger:"nunit;LogFilePath=.\features\nunit-test-reports\test-result.xml" \
--logger:"junit;LogFilePath=.\features\junit-test-reports\test-result.xml;MethodForma gitlab does not understand nunit, we need junit test data here
# for the gitlab test reporting
junit:
- ./features/junit-test-reports/*.xml
paths:
- ./features/junit-test-reports/*.xml
# the following xml files will be used in the pages job
- ./features/nunit-test-reports/*.xml
only:
- master
[...]
# here you publish your living documentation with the test results
pages:
stage: publish-pickles-reports
image: my-docker-registry/pickles:latest
dependencies:
- acceptance-test
script:
# this command generates a pickles documentation with test results
# in the ./public folder, which is the source folder for the gitlab
# pages
- |
mono /pickles/Pickles.exe --feature-directory=./features \
--output-directory=./public \
--system-under-test-name=my-test-app \
--system-under-test-version=$CI_COMMIT_SHORT_SHA \
--language=en \
--documentation-format=dhtml \
--link-results-file=./features/nunit-test-reports/test-result.xml \
--test-results-format=nunit3
artifacts:
paths:
- public
expires_in: 30 days
only:
- master
Le rapport pickles, ainsi que la spécification html dynamique pickles, peuvent être publiés sur une page gitlab comme dans l’extrait ci-dessus ou un conteneur docker qui peut ensuite être déployé sur votre cluster kubernetes, votre environnement Jelastic ou votre cdn.
Dernières paroles
Pour en revenir à la métaphore agile, j’espère qu’il est clair pour toute équipe SCRUM que « Product Owner » est un synonyme de « M. / Mme Clarté ». Un PO doit avoir ses exigences claires comme de l’eau de roche avant de les remettre à ses équipes de développement pour la mise en œuvre. En outre, pour éviter les surprises à la fin d’un sprint, un PO a besoin d’une mesure claire et en direct de la façon dont le sprint se déroule. Et un tableau d’épuisement du sprint ne signifie absolument rien quant à la quantité de logiciel fonctionnel que l’équipe a produit. Bien sûr, ma suggestion ne permettra pas d’éviter les échecs à tout moment, mais elle contribuera au moins à réduire les échecs et à rendre les parties prenantes plus heureuses.
Par ailleurs, lorsque de nouveaux arrivants rejoignent votre équipe de développement et que vous souhaitez qu’ils soient immédiatement productifs, vous pouvez considérer les fonctionnalités de Gherkin et les implémentations des étapes correspondantes comme une sorte de « bricolage » avec des conseils de haut niveau. Lorsqu’ils exécutent les tests des fonctionnalités, ils obtiennent un retour d’information autonome sur l’état d’avancement de leur mise en œuvre. L’architecture globale a déjà été définie, le nouveau venu n’a plus qu’à combler les lacunes par des détails de mise en œuvre. Il en va de même lorsque vous devez déléguer le développement d’un logiciel à une société tierce. Au lieu de rédiger de longs documents Word, vous pourriez essayer la méthodologie décrite dans ce billet. Le code ne ment pas et ne peut pas être mal interprété. Les documents Word peuvent l’être, surtout lorsque vous êtes, par exemple, une entreprise suisse qui rédige ses documents en anglais pour une entreprise de République tchèque. Dans ce cas, même si tout le monde a un bon niveau d’anglais, les contextes culturels font qu’il est parfois difficile pour des personnes de différents pays de se comprendre clairement, ce qui transforme la délégation du développement logiciel en un jeu de chuchotements chinois.